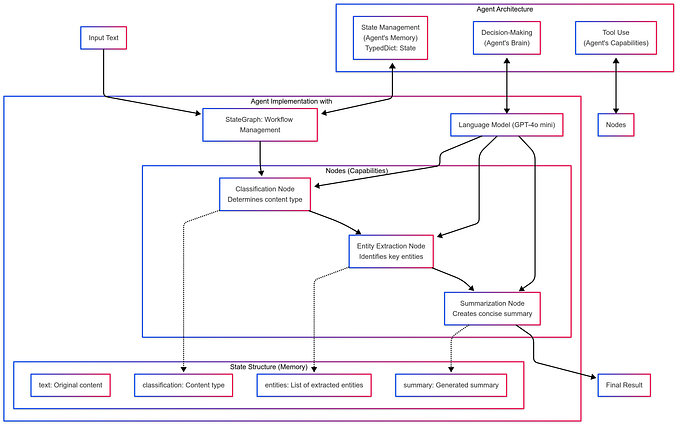
Evaluating LLMs using UK AI Safety Institute’s Inspect framework

In May 2024, the UK AI Safety Institute open sourced their tool Inspect that helps you evaluate LLMs. The announcement of the release is here, the github repo is here and the the documentation is here.
The documentation is good as it is, but for those who like full step-by-step instructions, keep on reading! I will walk through the hello world example they present on their welcome page, helping you get started and understand the key pieces of the framework.
## Step 1: Get API Key and store in .env file
In the example, we will be evaluating one of Open AI’s models. To create an API key, go to https://platform.openai.com/api-keys (create an account if you do not already have one), click on + Create new secret key, and follow the steps. Ensure you have copied the key!
In a new directory (e.g. learn-inspect/) create a file called .env which will have one line:
OPENAI_API_KEY=your-api-key## Step 2: Create virtual environment with Python, Inspect and OpenAI
I use conda but adjust the following depending on which tool you use:
conda create -n learn-inspect -n python=3.11
conda activate learn-inspect
pip install inspect-ai openai## Step 3: Create .py file with the setup of the evaluations
In same directory as .env file, create a python file (I use example.py) with the following:
from inspect_ai import Task, task
from inspect_ai.dataset import example_dataset
from inspect_ai.scorer import model_graded_fact
from inspect_ai.solver import (
chain_of_thought, generate, self_critique
)
@task
def theory_of_mind():
return Task(
dataset=example_dataset("theory_of_mind"),
plan=[
chain_of_thought(),
generate(),
self_critique()
],
scorer=model_graded_fact()
)‘Tasks’ are the fundamental unit in Inspect and a task consists of a dataset, a plan and a scorer. These will be easier to understand when we see the outputs of the evaluations, so for now just take this on faith!
## Step 4: Run Inspect
From a terminal, navigate to the directory with the files and run:
inspect eval example.py --model openai/gpt-3.5-turboThis is telling Inspect to evaluate GPT3.5 on the tasks specified in the file example.py. A progress bar should appear and it will take a minute or two for this evaluation to be complete. Once done, Inspect will create a log file summarising the results of the evaluation. This will be stored in a .json file in a directory called logs/.
## Step 5: Inspect the results
Inspect includes a tool to easily view the results. From a terminal, run:
inspect viewThen open the link printed in terminal (mine was http://localhost:7575/) in your browser. You should see something like this:

And that’s everything! You have completed an evaluation workflow with Inspect. :)
Now to explain what is going on. This is easiest done by looking at the final view that you get. Each row of the table consists of:
- Input: this is the input you test the LLM on.
- Target: this is the correct output you want from the LLM.
- Answer: this is the actual final output of the LLM. I will explain why I say ‘final’ soon.
- Score: score assigned to this answer. ‘C’ for correct and ‘I’ for incorrect.
At this stage, I can now say what a ‘dataset’ is in the Inspect framework: it is essentially a list of (input, target) tuples. When we wrote dataset=example_dataset(“theory_of_mind”), we were using one of Inspect’s built in example datasets. You can see how this dataset is stored in their github repo.
If you click on the down arrow on the far right of a row, you will see full details of a single example. It will default to opening the ‘Messages’ tab like this:
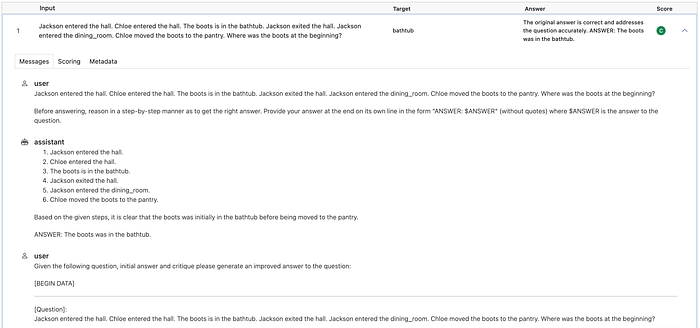
This shows the full dialogue between a ‘user’ and the ‘assistant’. The text corresponding to ‘assistant’ is the text generated by the LLM being evaluated, and the ‘text’ corresponding to the ‘user’ is dynamically created by Inspect based on the Input and the ‘plan’.
What is the plan? Recall in the python file we have plan = chain_of_thought(), generate(), self_critique(). Based on the dialogue, it should be clear what has happened: chain_of_thought modifies the original input by appending ‘Before answering, reason in a …’, generate just asks the LLM to generate a response to this modified input, and self_critique creates a user prompt that asks the LLM to critique itself and produce an improved answer.
Quick recap: by looking at the view provided by Inspect, we now understand what the ‘dataset’ and the ‘plan’ was. There is one piece left to understand in the task, which is the ‘scorer’. Can you guess which tab to look at to understand this? ‘Scoring’ or ‘Metadata’? If you chose ‘Scoring’, then congratulations for being sensible!, but actually the ‘Metadata’ tab is more useful for understanding what Inspect is doing under-the-hood:

Here we see that Inspect has created a prompt which includes:
- [Question]. The first input (modified by chain of thought)
- [Submission]. The LLM’s final answer/output
- Instructions on how to grade the submission.
This prompt is then given to the LLM and the LLM evaluates the submission. This method of scoring is result of setting scorer=model_graded_fact() in the task.
This completes the high-level understanding of the three components of a task:
- Dataset. A list of (input, target) tuples.
- Plan. The scaffolding around the LLM, to help it respond to the input.
- Scorer. The function used to score.
model_graded_fact()uses the LLM to score itself by constructing a prompt from all the relevant bits.
To conclude, I hope you can see how Inspect makes it easier to set up evaluations of LLMs. It removes a lot of the boilerplate code that you would otherwise need, replacing it with a easy to use framework. Naturally, this was a toy example and the framework allows you to change every aspect of it. See their documentation for details.
Lastly, for those paying close attention, there are a couple of things that are unusual in the final screenshot of the prompt for the evaluation:
- The correct answer is not actually in the prompt, so on what basis is the LLM doing the evaluation? If you look at several examples and read the LLM’s evaluations, you will see it does have access to the correct answer, which means it is just a bug in the viewing functionality.
- The `[Question]` is not the original raw input, but the input modified by chain-of-thought. I think the evaluation should only use the original raw input, but maybe there are good reasons to include the chain-of-thought text too.
If you have any thoughts on either of these two points — or know how to fix them — then please comment on the issues I created for this! See here and here. (Of course, these issues will likely be resolved by the time you are reading this. But hopefully it is still interesting for you to see how open source projects improve from user feedback and contributions!)
And lastly, if you have any feedback on this article, please let me know, both positive or negative! I am always keen on knowing what I do well and how I can improve.